Early Stage Researcher Muhammed Adil Yatkin introduces his topic “Stress state dependent fracture criteria determination for large shell structures using deep learning methods”, supervised by Professor Mihkel Kõrgesaar.
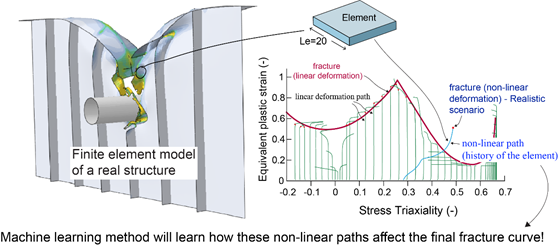
Today, ship collision and grounding analyses are performed using non-linear finite element simulations. The reliability of these simulations is directly related to the fracture criterion. Current fracture criteria are calibrated on the assumption that the deformation path (loading history) is linear, while it can be highly non-linear. The idea of this work is to generate a machine learning-based fracture criterion that accounts for this non-linear behavior before fracture onset.
As it is known, machine learning applications or artificial intelligence technologies have entered every area of our lives today. We can give examples such as self-driving vehicles, image recognition, object detection, text recognition or speech recognition. The main reason behind these developments is that deep learning methods have reached a very high level in recent years. Deep Learning is a subfield of machine learning concerned with algorithms inspired by the structure and function of the brain called artificial neural networks.
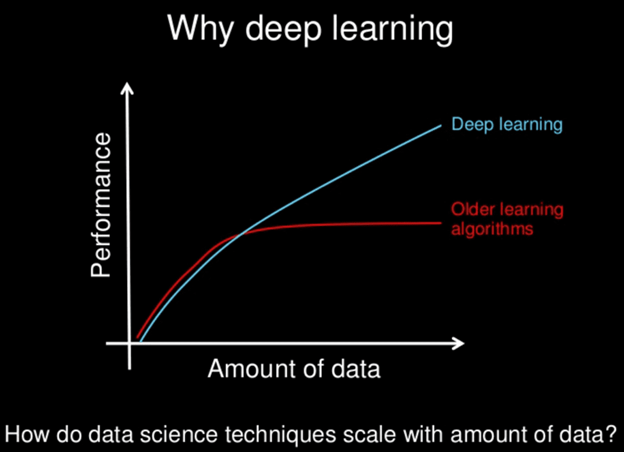
The concept and science behind artificial neural networks have been around for decades. However, it has only been in the last few years that the possibilities of neural networks have become reality and helped the AI industry evolve rapidly.
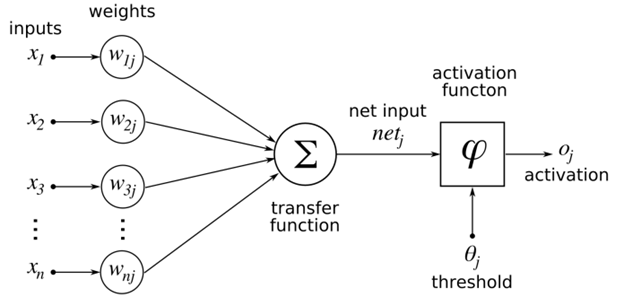
The basic component of artificial neural networks are artificial neurons. Essentially, an artificial neuron consists of a transformation function and an activation function, along with a set of weighted inputs. The activation function at the end corresponds to the axon of a biological neuron. Weighted inputs correspond to inputs from a biological neuron that receives electrical impulses moving in the brain and works to transmit them to subsequent layers of neurons.
Artificial neurons, which are part of artificial neural networks, drive deep learning and machine learning capabilities. They help computers “think like humans” and produce more complex cognitive results. Each neuron takes input from several other neurons, multiplies them by their assigned weights, adds them, and transmits the sum to one or more neurons. Some artificial neurons may apply an activation function to the output before moving on to the next variable.
In essence, this may sound like a trivial math operation. But when you place and stack hundreds, thousands and millions of neurons in multiple layers, you get an artificial neural network (ANN) that can perform very complex tasks like classifying images or recognizing speech.
Neural networks consist of an input layer that receives data from external sources (data files, images, hardware sensors, microphones, etc), of one or more hidden layers that process the data, and of an output layer that provides one or more data points. It depends on the function of the network. For example, a neural network that detects people, cars and animals will have a three-node output layer. A network that classifies bank transactions as secure or fraudulent will have a single output.
Artificial neural networks are also divided into types. The reason for these different types of neural networks is to adapt them to different tasks encountered in daily life. For example, if we are dealing with a computer vision task, then we usually use convolutional neural networks, and if we are dealing with a natural language processing problem, we use recurrent neural networks that deal with sequential data, such as text classification.
Sequence models are the machine learning models that input or output sequences of data. Sequential data includes text streams, audio clips, video clips, time-series data etc. Recurrent Neural Networks (RNNs) is a popular algorithm used in sequence models.
The main advantage of using RNNs instead of standard neural networks is that the features are not shared in standard neural networks. Weights are shared across time in RNNs. RNNs can remember their previous inputs but Standard Neural Networks are not capable of remembering previous inputs. RNNs take historical information for computation. The task we want to achieve in our case is similar to music generation or image captioning, that is, we can consider our task as “one to many“.
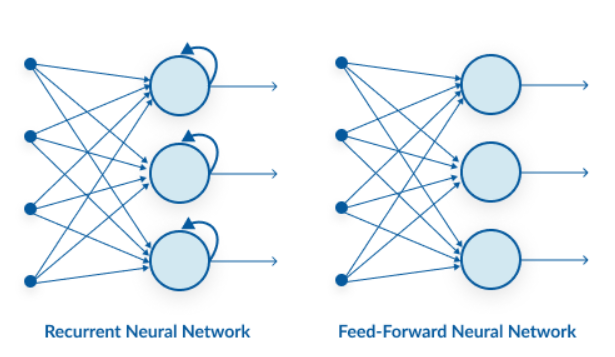
Normally, standard ANNs (Artificial Neural Networks) cannot capture sequential information in the input data but by adding a looping constraint on the hidden layer, the ANN(Artificial Neural Network) turns to an RNN – Recurrent Neural Network. As you can see here, an RNN has a recurrent connection on the hidden state. This looping constraint ensures that sequential information is captured in the input data.
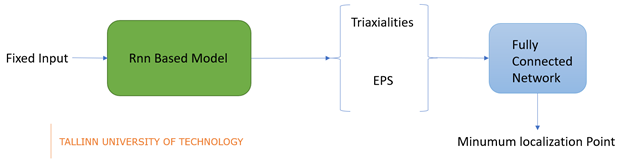
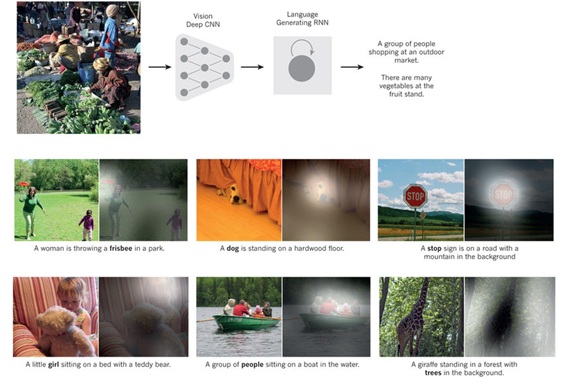
When we analyze the deformation paths of different thicknesses and triaxialities that come from crash simulations, these paths are highly non-proportional. Also, the way deformations are considered significantly affects the analysis results. Therefore, with a recurrent neural network model to be established, the full deformation path can be estimated, and localization points can be predicted with a second network. We see a similar task in image captioning. While we are giving an image as a fixed input, we are taking out different sized sentences so actually, our task is “one to many” prediction.
Overall, our goal is to build a model that can predict sequences based on a given constant input, using a recurrent neural network. As we have a lot of simulation data, we can train a machine learning model with these data and make sequence predictions. Although finite element models normally work at the back of these simulations, deep learning models can establish a connection between fixed inputs and sequential outputs. Later, we can train the sequences we have produced with this model as input into another model with manual labeling logic. In other words, our whole system will consist of two parts, the first model will make sequence predictions according to the given fixed input and the second model will predict minimum localization points.